
The original idea for therightup.news came from a conversation with a politically left-leaning friend about a year ago. While we’re worlds apart in our politics, we found some common ground in a shared view that reading “the news” – the Guardian and BBC in her case; /pol/ and various conservative blogs in mine – serves mainly to induce feelings of anger, annoyance and frustration, irrespective of one’s political ideology.
This led me to wonder if there were any alternatives to the relentless anger-porn of traditional news outlets, so I tried searching for sources of “good news”. Alas, I searched in vain, not least because “good” is, of course, highly subjective; the few sites that I found claiming to offer exclusively positive news turned out to be celebrations of globo-homo degeneracy, climate hokum and the anti-white identity politics we’re only too familiar with.
Ultimately I failed to find a right-leaning source of “good news.” Whether there’s a gap in the market to be exploited, or simply a lack of demand – because when it comes down to it, we get off on winding ourselves up and raging into the void – I’ll leave to the reader to decide.
But it set off a train of thought on the subject of customised news, filtered according to your preferences; news that’s tailored just for you.
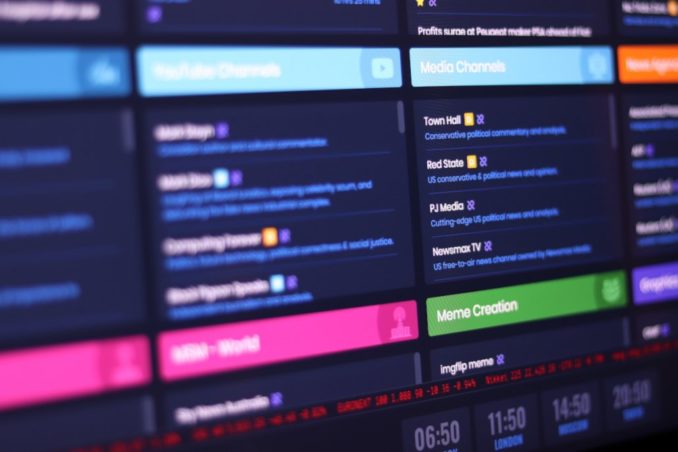
The other idea that inspired me to create therightup.news was a desire for an easy way to keep on top of the continual output of news sites and blogs that I frequent. I wanted a dashboard that showed me whenever a new article was published, and where I could see all the most recent news headlines; an overview of everything going on in the world, updated in real-time.
And, being the deplorable far-right nazi bigot that I am, I wanted it to reflect my own comfortable echo-chamber of right-leaning, anti-globalist views. Such a beast didn’t exist, as far as I could tell, so I decided to build it myself.
So much for the back-story, now onto the technical nitty-gritty for the GP nerds…
The project uses the WordPress platform. I figured that WordPress would provide a ready-built back-end administration area with user account handling and security, and an easy way to build and populate the database-driven elements using Custom Post Types.
On top of a fresh WordPress install, I created a custom theme and a custom plugin. The starting point for the theme (called, unsurprisingly, “TheRightUp”) was the HTML5 Blank theme boilerplate; for the plugin (called “PressReader”) I used the WordPress Plugin Boilerplate, an empty object-oriented plugin template.
In order to develop locally on my old Windows7 desktop I needed a suitable suite of windows-compatible back-end software and settled on XAMPP, which provides the Apache web server, MariaDB mySQL database, and PHP stack in an easy-to-install package.
There’s precious little HTML in the project, it’s mostly Javascript and CSS in the browser and PHP on the server, but I still needed a code editor. Previously I used Textpad, then more recently Notepad++, but for this project I moved on to Atom, which offered a plugin for automatic linting and beautifying. Plus it’s all dark with colour-coded syntax, which is cool and makes me feel like a hacker.
I wanted to use SASS for the CSS, and split the Javascript into individual files for each class so that everything would be tidy and organised when I revisit the code in six months and have completely forgotten everything I’ve done. To build and test I used Prepros, a handy visual front-end that transpiles Javascript using Babel – ensuring compatibility with older browsers – compiles SASS, and minifies and mangles the output. It watches your project folders for any changes, and does its magic every time you save a file, warning you if it finds any errors. As a bonus it also automatically updates the page you’re viewing in the browser, and synchronises browsers across multiple devices to help with debugging. Nice.
I didn’t fancy the cost of signing up with Browserstack, so for testing I’m using an old first generation iPad mini, a pathetically low spec Asus android tablet, a 4 year old Samsung Galaxy A5 and my 2012 Dell XPS all-in-one desktop. If it works on all those, it’ll work on anything.
So, on to the development itself…
Partly because I’m using Atom and my eyes have adjusted to the dark, and partly to reflect my evil, twisted nature, I decided to go for a dark theme. I initially intended to create light and dark versions, with a toggle to flip between CSS files, but when it came to it, I couldn’t be arsed. You can have any colour, as long as it’s black.
The custom WordPress theme is pretty basic, comprising the header bar (burger and logo), the footer (including the code for the clocks) and the burger drop-down help screen. The clocks use moment – a javascript plugin that handles the timezone calculations – it’s 84k of minified overkill but I just couldn’t for the life of me get javascript’s in-built Date class to work correctly on the old ipad mini, so eventually I gave up and threw a plugin at it in frustration. The shameful decadence of such gross inefficiency may force me to revisit this at some point.
There are only four pages in the site – the homepage (which is essentially a blank page until populated by Javascript) and the three static legal pages – privacy, terms and cookies.
Moving onto the meat in my sandwich: the custom Press Reader plugin.
The plugin is divided into two main areas: the Javascript that handles all the front end work in the browser, and the PHP cron job that gathers the news and blog feeds and prepares the data arrays.
The cron task relies on three Custom Post Types that are used to store the news sources, the blogs & other resources, and the financial ticker data. Out of the box, WordPress provides two post types: Posts (normally containing blog posts or articles such as this one) and Pages (normally containing static pages such as the home and contact pages for example.)
But you can create your own Custom Post Types to store any other type of data you fancy. I used the free Custom Post Type UI plugin to create three new CPTs in the admin, and another free plugin, Advanced Custom Fields, to specify the database fields that I needed.
When I first started building the site, I was expecting to have to scrape the HTML of the various news websites, extracting the article headlines and links from the HTML using customised rules for every site – rules that I’d need to keep fixing whenever a site was modified or redesigned.
Fortunately I was mistaken. It transpires that almost every news site, aggregator and blog in the entire world has an RSS feed. Go to the homepage of almost any news site or blog you like, stick /rss or /feed at the end of the URL and Bob’s your uncle.
A quick word about stackoverflow.com – I couldn’t have done any of this without it. If you’re stuck on how to do something, and providing that you can formulate the question, chances are the contributors at SO have already provided the answer. It’s not much of an exaggeration to say that most of the code on this project was written by the immensely talented folks at SO – I merely ferried it from there to here a few lines at a time and changed the names of the variables.
Back to the code…
The cron task runs on the server every five minutes and pulls in the RSS XML feeds from the news sites. Each site has a polling frequency specified in the RSS header – usually 1 hour – but you can, and I do, ignore that, and use my own values. I set them all slightly differently so that they aren’t all collected at the same time, making it more likely that the user will see a steady flow of new articles arrive in the front-end. The individual feeds are variously set at between 30 and 90 minutes.
I don’t know if my IP address would get blocked or throttled if they were pulled in more frequently, but in any case I’m trying to be a good neighbour and not hit them too often. Also there are resource usage limits on my shared hosting account, and it turns out this website is using a fair old chunk of them.
The PHP code is split into various classes for the news sites, blogs & resources, and financial ticker. Subservient to the news class are classes for the news categories, the feeds, and the articles. Each XML feed is parsed using PHP’s DOM extension classes, and individual articles are sorted and filtered by category keywords, title keywords and url keywords into news categories, and then merged into a single json-encoded array ready to be collected by the front end Javascript.
Blogs and resources are much the same, although with those only the time and date of the most recent blog post is stored. Youtube RSS feeds use a slightly different format to the WordPress feeds, just to be awkward.
On the browser side, the Javascript is divided into objects containing functions that deal with section layout; collecting and displaying updates; and user events, such as clicks and keypresses. As JQuery is included by default with WordPress I used it throughout for speed of coding and convenience.
The fancy draggable grid is handled by a Javascript plugin called muuri, which is Finnish for “wall”. See, you learn something new every day. Unless you’re Finnish.
News updates are collected via AJAX calls to the server. The front end sends a timestamp for each of the data arrays back to the server, the server compares them to the versions stored in the WordPress options table, and if the cron job has updated an array in the meanwhile, the server sends back the updated version. The browser checks for updates every 2 minutes.
My partner in evil deeds, the good lady LovePump, has been sharpening her front end design skills using Figma – a new-ish and very nice graphic design app expressly aimed at web development – so she was pressed into service designing the look and feel, with Google’s Material Design as a starting point for inspiration.
Once a component had been designed in Figma, the sizing, colours, spacing etc. of each element were transferred across into the CSS. Fonts were chosen from Google Fonts; we picked Poppins for the primary font, Oswald for the logo and Share Tech for the ticker.
For the icons we used flaticon.com, a site that allows you to use their icons for free provided you credit the designer. I like free, so a credit panel was added at the bottom of the main page. Flaticon provides an option to download icons as SVG vector files. Vector graphics allow the icons to scale to any size whilst maintaining perfectly crisp edges, and generally involve smaller files. For this project the file containing all the graphics for the site in svg format comes to only 75k.
Testing on different devices presented some useability issues. On the desktop when using the mousewheel to scroll the page, I often found myself scrolling an individual news category instead, which was annoying, so I added a scroll suspend button with a quick Control key toggle. A similar problem with scrolling on tablets was solved with an extra wide margin toggle, providing more finger space down the sides of the screen.
I was reluctantly forced to disable the drag and drop reordering on touch devices as muuri was just too greedy with the touch input, making scrolling the sections almost impossible. On mobile-sized displays I decided to start all the sections closed by default, replacing the icons in the title headers with animated up/down buttons instead.
Finally I added the ability to choose different section widths and heights, to suit screen resolutions and personal preference. Local Storage, rather than cookies, are used to save the layout preferences in the browser.
A few minor jobs remained before going live for the first time; legalese was added to the privacy, terms and cookies pages using free templates from Docular with some appropriate modifications; the Cookie Consent plugin was a project I’d worked on last year – my first custom-built wordpress plugin – so I added that; and I set up a PayPal account for donations and added buttons in the undoubtedly forlorn hope that some kindly souls might find the project useful enough to contribute to the overheads.
I posted some requests on GP asking for suggestions of news sites and blogs to add, and I spent a few days trawling through those and wading through blogrolls gathering content and populating the database.
Finally, a couple of weeks ago I uploaded the site and posted a comment to that effect on GP – about 40 people hit the site at once, so I was able to monitor resource use and see how the site stood up. It wasn’t great. Using the hosting control panel, I watched the CPU usage and “account executions” shoot up, to levels that, if sustained, would quickly see the hosting account exceed the allowed resource caps and get my account throttled or closed.
More work required!
The original RSS download and parsing script that’d appropriated from stackexchange implemented a simple caching system using a text file to store the feed. I’d built on this, and as a result I was reading and writing a couple of hundred cache files in my feed folder whenever the cron task ran, and I was also storing the data arrays as files which were being read on every browser update request.
So I decided to bite the bullet and re-write all file operations using the WordPress database instead. I added some extra fields to the Custom Post Types and cached the article arrays in those, and also added an admin page and moved all the constants and tweakable variables into the WP Options table. I’m hopeful that these changes will lighten the load on the server sufficiently, but only time will tell.
Finally I added a PHP class to handle error logging and send me regular email log summaries, and went through all the code tidying up and adding comments to all the class properties, like a good boy. The entire project took about seven weeks of full-time work.
Future plans include some suggestions made by GP commenters, including further user customisation options, such as hiding unwanted sections and publications, and adding twitter feeds from our favourite tweeters, like Trump and our very own Puffin twitter stars.
I hope some of you might find therightup.news useful, and if you have any further ideas, send them my way – tips@therightup.news.
Suggestions for other nefarious, far-right coding projects will also be most welcome.
© LickMyLovePump 2020
The Goodnight Vienna Audio file


